搜索到
195
篇与
后端
的结果
-

-
修改mysql 默认字符集 修改前mysql> show variables like 'char%'; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.00 sec)修改配置文件vim /etc/my.cnf# For advice on how to change settings please see # http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html [mysqld] # # Remove leading # and set to the amount of RAM for the most important data # cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%. # innodb_buffer_pool_size = 128M # # Remove leading # to turn on a very important data integrity option: logging # changes to the binary log between backups. # log_bin # # Remove leading # to set options mainly useful for reporting servers. # The server defaults are faster for transactions and fast SELECTs. # Adjust sizes as needed, experiment to find the optimal values. # join_buffer_size = 128M # sort_buffer_size = 2M # read_rnd_buffer_size = 2M datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid lower_case_table_names=1 [client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] character-set-server=utf8mb4重启service mysqld restart
-
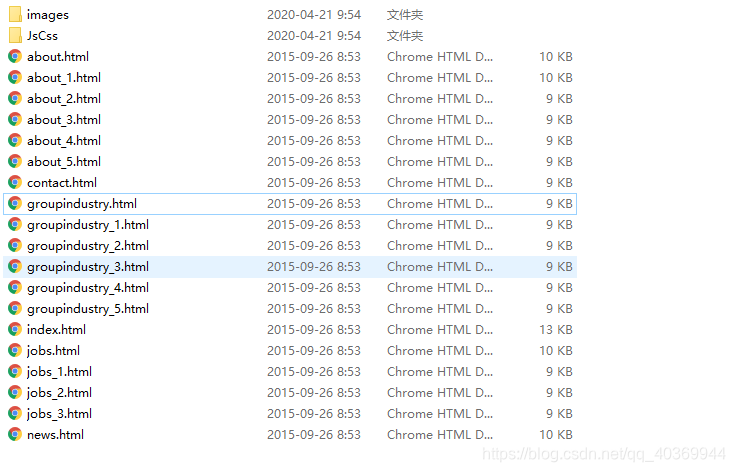
Public CMS搭建网站(一) 前言在使用Public CMS搭建网站之前,没有安装的小伙伴请先去安装模板文件首先准备好一套html模板,可任选一套简单的模板进行练习,可以百度下载一些,这里就不多做介绍示例这里使用案例的模板是一套官网模板 一、准备工作上传样式文件讲css文件及js文件转出压缩包,上传 解压解压完后删除之前上传是压缩包文件 上传模板 修改路径模板文件管理以index.html为例,点击界面空白处选择网站文件选择完之后会在界面中多处这样一段代码可将${site.sitePath}复制到每个路径前面如:配置站点可配置为自己服务器ip或域名 访问http://站点地址/publiccms/index.html 基本的模板导入及路径配置就到这里了
-
-
mqtt websocket web消息推送(房间消息发送) 部分html<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title></title> <script src="js/mqttws31.js" type="text/javascript" /> <script> var hostname = 'ip', port = 9001, //websocket 端口 clientId = 'client-2020', timeout = 5, keepAlive = 50, cleanSession = false, ssl = false, userName = 'test',//mqtt 账户 password = 'test',//mqtt 密码 topic = 'test/test';//主题 client = new Paho.MQTT.Client(hostname, port, clientId); //建立客户端实例 var options = { invocationContext: { host : hostname, port: port, path: client.path, clientId: clientId }, timeout: timeout, keepAliveInterval: keepAlive, cleanSession: cleanSession, useSSL: ssl, userName: userName, password: password, onSuccess: onConnect, onFailure: function(e){ console.log(e); } }; client.connect(options); //连接服务器并注册连接成功处理事件 function onConnect() { console.log("onConnected"); client.subscribe(topic); } client.onConnectionLost = onConnectionLost; //注册连接断开处理事件 client.onMessageArrived = onMessageArrived; //注册消息接收处理事件 function onConnectionLost(responseObject) { console.log(responseObject); if (responseObject.errorCode !== 0) { console.log("onConnectionLost:"+responseObject.errorMessage); console.log("连接已断开"); } } function onMessageArrived(message) { console.log("收到消息:"+message.payloadString); } function send(){ var s = document.getElementById("msg").value; if(s){ s = "{time:"+new Date().Format("yyyy-MM-dd hh:mm:ss")+", content:"+(s)+", from: web console}"; message = new Paho.MQTT.Message(s); message.destinationName = topic; client.send(message); document.getElementById("msg").value = ""; } } var count = 0; function start(){ window.tester = window.setInterval(function(){ if(client.isConnected){ var s = "{time:"+new Date().Format("yyyy-MM-dd hh:mm:ss")+", content:"+(count++)+", from: web console}"; message = new Paho.MQTT.Message(s); message.destinationName = topic; client.send(message); } }, 1000); } function stop(){ window.clearInterval(window.tester); } Date.prototype.Format = function (fmt) { //author: meizz var o = { "M+": this.getMonth() + 1, //月份 "d+": this.getDate(), //日 "h+": this.getHours(), //小时 "m+": this.getMinutes(), //分 "s+": this.getSeconds(), //秒 "q+": Math.floor((this.getMonth() + 3) / 3), //季度 "S": this.getMilliseconds() //毫秒 }; if (/(y+)/.test(fmt)) fmt = fmt.replace(RegExp.$1, (this.getFullYear() + "").substr(4 - RegExp.$1.length)); for (var k in o) if (new RegExp("(" + k + ")").test(fmt)) fmt = fmt.replace(RegExp.$1, (RegExp.$1.length == 1) ? (o[k]) : (("00" + o[k]).substr(("" + o[k]).length))); return fmt; } </script> </head> <body> <input type="text" id="msg"/> <input type="button" value="Send" onclick="send()"/> <input type="button" value="Start" onclick="start()"/> <input type="button" value="Stop" onclick="stop()"/> </body> </html> 注意事项 1、如果使用wss需要配置nginxssl改为trueport 改为 443 2、如果使用ws则不需要配置nginxssl改为falseport改为mqtt服务ws开放的端口源码:https://github.com/Uncle-LiuY/demo-websocket项目首页:http://192.168.0.82:8888/room
-
-
-
MySQL安装及数据库操作、编程介绍 Mysql 一、下载及安装 1.1 下载MySQL安装包地址:http://dev.mysql.com/downloads/mysql/1.2安装MySQL 安装MySQL的三种方式:l 在线安装版,下载:mysql-installer-web-community.exel 离线安装版,下载:mysql-installer-community.exe解压缩版,下载:Windows (x86, 64-bit), ZIP Archive 1.3安装第三方插件Navicat for MySQL 二、数据库操作 2.1创建数据库 create database数据库名;或CREATE DATABASE IF NOT EXISTS数据库名DEFAULT CHARSETutf8 COLLATEutf8_general_ci;默认的数据库编码集:utf8(即UTF-8),collate表示排序规则为utf8_general_ci。 注意:MySQL存入汉字乱码问题解决方案:(1)在创建数据库时设置编码:字符集:utf8 -- UTF-8 Unicode排序规则:utf8_general_ci(2)找到MySQL的安装路径的my.ini文件,打开并修改:default-character-set=utf82.2使用数据库use 数据库名;2.3删除数据库drop database 数据库名;2.4设置默认日期:mdate TIMESTAMP DEFAULT CURRENT_TIMESTAMP2.5修改默认值:ALTER TABLE TB_3ALTER column upwd set DEFAULT '123456';2.6标识列Uuid decimal primary key AUTO_INCREMENT;2.7创建表结构CREATE TABLE[if no exists]表名称(列名称1 数据类型,列名称2 数据类型,列名称3 数据类型,....)2.8修改表结构ALTER TABLE 语句用于在已有的表中添加、修改或删除列。如需在表中添加列,请使用下列语法:ALTER TABLE table_nameADD column_name datatype要删除表中的列,请使用下列语法:ALTER TABLE table_nameDROP COLUMN column_name注释:某些数据库系统不允许这种在数据库表中删除列的方式 (DROP COLUMN column_name)。要改变表中列的数据类型,请使用下列语法:ALTER TABLE table_nameALTER COLUMN column_name datatype2.9复制表CREATE TABLE tasks_bak LIKEtasks;2.10删除表drop table 表名;2.11修改表名RENAME TABLE旧表名 TO新表名; 2.12表数据操作:增删改增加一条:INSERT INTO表名(列1, 列2,……) VALUES(值1, 值2,……);增加多条:INSERT INTO表名(列1, 列2,……)VALUES(值1, 值2,……),(值1, 值2,……),(值1, 值2,……),……;INSERT INTOtable_1 --table_1表要存在SELECTc1, c2 FROMtable_2;添加密码时对字符串进行MD5加密:INSERT INTO table_1(upwd) VALUES(MD5(‘123’));删除表数据:Delete fromtb_name whereuname=’admin’;Truncate table 表名; --仅删除表格中的数据修改表数据:Updatetb_name setupwd=’abc’ whereuname=’admin’;三、数据类型字符类型Char Varchar text blob数值类型Int integer float double decimal日期类型Date time datetime timestamp 3.1数值类型:1. 整型指定长度是没有意义的。如int(5)只能限定长度,如果在后面加上unsigned 表示无符号,即非负整数。如果int(5) unsigned zerofill,存入12,则实际存储数据为00012。2. 浮点数值float、double、decimal,其中float和double相比decimal效率高,decimal可理解成是用字符串进行处理。 3.2字符类型:1. Varchar存储可变长字符串,比定长类型更节省空间。存储的内容超出设置长度时,会被截断。2. Char是定长的,根据定义的长度分配足够的空间。适合存储很短的字符串或值接近同一个长度的字符串。多出的部分用空格填充。超出设置的长度同样会被截断。3. 使用策略:对于经常变更的数据来说,char比varchar更好,因为char不容易产生碎片。对于非常短的列,char比varchar在存储空间上更有效率。使用时注意分配需要的空间,更长的列排序时会消耗更多内存。尽量避免使用text/blob类型,查询时会使用临时表,导致严重的性能开销。数据类型描述CHAR(size)保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多 255 个字符。VARCHAR(size)保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 255 个字符。注释:如果值的长度大于 255,则被转换为 TEXT 类型。TINYTEXT存放最大长度为 255 个字符的字符串。TEXT存放最大长度为 65,535 个字符的字符串。BLOB用于 BLOBs (Binary Large OBjects)。存放最多 65,535 字节的数据。MEDIUMTEXT存放最大长度为 16,777,215 个字符的字符串。MEDIUMBLOB用于 BLOBs (Binary Large OBjects)。存放最多 16,777,215 字节的数据。LONGTEXT存放最大长度为 4,294,967,295 个字符的字符串。LONGBLOB用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。ENUM(x,y,z,etc.)允许你输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在插入的值,则插入空值。注释:这些值是按照你输入的顺序存储的。可以按照此格式输入可能的值:ENUM('X','Y','Z')SET与 ENUM 类似,SET 最多只能包含 64 个列表项,不过 SET 可存储一个以上的值SMALLINT(size)-32768 到 32767 常规。0 到 65535 无符号*。在括号中规定最大位数。MEDIUMINT(size)-8388608 到 8388607 普通。0 to 16777215 无符号*。在括号中规定最大位数。INT(size)-2147483648 到 2147483647 常规。0 到 4294967295 无符号*。在括号中规定最大位数。BIGINT(size)-9223372036854775808 到 9223372036854775807 常规。0 到 18446744073709551615 无符号*。在括号中规定最大位数。FLOAT(size,d)带有浮动小数点的小数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。DOUBLE(size,d)带有浮动小数点的大数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。DECIMAL(size,d)作为字符串存储的 DOUBLE 类型,允许固定的小数点。 操作符描述=等于<>不等于>大于<小于>=大于等于<=小于等于BETWEEN在某个范围内LIKE搜索某种模式注释:在某些版本的 SQL 中,操作符 <> 可以写为 !=。3.3日期类型:1. 尽量用timestamp,空间效率高于datetime。2. 用整数保存时间戳通常不方便处理。数据类型描述DATE()日期。格式:YYYY-MM-DD注释:支持的范围是从 '1000-01-01' 到 '9999-12-31'DATETIME()*日期和时间的组合。格式:YYYY-MM-DD HH:MM:SS注释:支持的范围是从 '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59'TIMESTAMP()*时间戳。TIMESTAMP 值使用 Unix 纪元('1970-01-01 00:00:00' UTC) 至今的描述来存储。格式:YYYY-MM-DD HH:MM:SS注释:支持的范围是从 '1970-01-01 00:00:01' UTC 到 '2038-01-09 03:14:07' UTCTIME()时间。格式:HH:MM:SS 注释:支持的范围是从 '-838:59:59' 到 '838:59:59'YEAR()2 位或 4 位格式的年。注释:4 位格式所允许的值:1901 到 2155。2 位格式所允许的值:70 到 69,表示从 1970 到 2069。 3.4枚举类型:1. 把不重复的数据存储为一个预定义的集合。2. 有时可以使用ENUM代替常用的字符串类型。3. ENUM存储非常紧凑,会把列表值压缩到一个或两个字节。4. ENUM在内部存储时,其实存的是整数。5. 尽量避免使用数字作为ENUM的常量,因为容易混乱。排序是按照内部存储的整数。四、约束4.1主键约束:PRIMARY KEY 唯一、不重复、不为空;每个表都应该有一个主键,并且每一个表只能有一个主键。UUID int PRIMARY KEY;或CONSTRANIT UUID PRIMARY KEY修改主键约束:ALTER TABLE 表名ADD PRIMARY KEY (UUID) 删除主键约束:ALTER TABLE 表名DROP PRIMARY KEY 4.2外键约束:FOREIGN KEY外键创建在从表(副表)中,从表中的FOREIGN KEY指向主表中的PRIMARY KEY。Kid decimal REFERENCES 主表名(主键)或CONSTRANIT 外键名 FOREIGN KEY (kid) REFERENCES主表名(主键); 修改外键约束:ALTER TABLE OrdersADD FOREIGN KEY (外键字段) REFERENCES 主表名(主键字段); 删除外键约束:ALTER TABLE OrdersDROP FOREIGN KEY 外键名; 4.3空值约束:NOT NULLUname varchar(20) NOT NULL; 4.4唯一约束:UNIQUECodeID varchar(20) UNIQUE; 修改唯一约束:ALTER TABLE PersonsADD UNIQUE (Id_P); 删除唯一约束:ALTER TABLE PersonsDROP INDEX uc_PersonID; 4.5检查约束:CHECKUage decimal(3) CHECK(uage>0 and uage<150); 修改检查约束:ALTER TABLE PersonsADD CHECK (Id_P>0) 删除检查约束:ALTER TABLE PersonsDROP CHECK chk_Person 4.6默认值约束:DEFAULTUsex varchar(4) DEFAULT‘男’ ; 五、查询操作2.1简单查询--查询列名称不重复数据SELECT DISTINCT 列名称 FROM 表名称 --查询前5的SELECT * FROM Persons LIMIT 5; --in操作符SELECT * FROM Persons WHERE LastName IN('Adams','Carter');SELECT * FROM Persons WHERE LastName BETWEEN 'Adams' AND 'Carter' 5.2条件查询SELECT * FROMtable_name WHERE 条件 AND|OR 条件 --查询语句是从employees表中随机选择一个其职位是Sales Rep的员工SELECT employeeNumber FROM employeesWHERE jobtitle = 'Sales Rep'ORDER BY RAND()LIMIT 1; 模糊查询Select * from tb_name where name like ‘_李%’;注意:模糊查询中有 _和%,没有[]5.3分组统计GROUP BY子句:案例:订单(orders)和订单详细(orderdetails)表,它们的ER图如下: 要按状态获取所有订单的总金额,可以使用orderdetails表连接orders表,并使用SUM函数计算总金额。查询:SELECTstatus, SUM(quantityOrdered * priceEach) AS amountFROM ordersINNER JOIN orderdetails USING (orderNumber)GROUP BY status;类似地,以下查询返回订单号和每个订单的总金额。SELECT orderNumber,SUM(quantityOrdered * priceEach) AS totalFROM orderdetails GROUP BY orderNumber; Having子句:使用HAVING子句过滤GROUP BY子句返回的分组。查询使用HAVING子句来选择2013年以后的年销售总额SELECT YEAR(orderDate) AS year, SUM(quantityOrdered * priceEach) AS totalFROM orders INNER JOIN orderdetails USING (orderNumber)WHERE status = 'Shipped'GROUP BY yearHAVING year > 2013; 5.4排序SELECT Company, OrderNumber FROM Orders ORDER BY Company 5.5分页--从1000行开始扫描后20条数据Select * from tb_name order by id desc limit 1000,20;--查询21~30的数据(分页)Select * from tb_name order by id desc limit 21,30;六、SQL 通配符在搜索数据库中的数据时,SQL 通配符可以替代一个或多个字符。SQL 通配符必须与 LIKE 运算符一起使用。通配符描述%替代一个或多个字符_仅替代一个字符[charlist]字符列中的任何单一字符[^charlist]或者[!charlist]不在字符列中的任何单一字符 6.1使用 % 通配符例子 1现在,我们希望从上面的 "Persons" 表中选取居住在以 "Ne" 开始的城市里的人:SELECT * FROM PersonsWHERE City LIKE 'Ne%' 6.2使用 _ 通配符例子 1现在,我们希望从上面的 "Persons" 表中选取名字的第一个字符之后是 "eorge" 的人:SELECT * FROM PersonsWHERE FirstName LIKE '_eorge' 6.3使用 [charlist] 通配符例子 1现在,我们希望从上面的 "Persons" 表中选取居住的城市以 "A" 或 "L" 或 "N" 开头的人:SELECT * FROM PersonsWHERE City LIKE '[ALN]%'例子 2现在,我们希望从上面的 "Persons" 表中选取居住的城市不以 "A" 或 "L" 或 "N" 开头的人:SELECT * FROM PersonsWHERE City LIKE '[!ALN]%' 6.4SQL Alias通过使用 SQL,可以为列名称和表名称指定别名(Alias)。表的 SQL Alias 语法SELECT column_name(s)FROM table_nameAS alias_name列的 SQL Alias 语法SELECT column_name AS alias_nameFROM table_name 七、索引7.1创建索引CREATE INDEX 索引名 ON 表名(列名) 在表上创建一个简单的索引。允许使用重复的值:CREATE INDEX index_nameON table_name (column_name)注释:"column_name" 规定需要索引的列。7.2创建唯一索引CREATE UNIQUE INDEX 索引名 ON 表名(列名) 在表上创建一个唯一的索引。唯一的索引意味着两个行不能拥有相同的索引值。CREATE UNIQUE INDEX index_nameON table_name (column_name) 创建表时直接指定:在创建表时,设置某列为主键或唯一约束,都会自动创建主键索引和唯一索引。 7.3删除索引DROP INDEX 索引名 ON 表名 我们可以使用 DROP INDEX 命令删除表格中的索引。ALTER TABLE table_name DROP INDEX index_nameDROP TABLE 表名称DROP DATABASE 数据库名称 7.4CREATE INDEX 实例本例会创建一个简单的索引,名为 "PersonIndex",在 Person 表的 LastName 列:CREATE INDEX PersonIndexON Person (LastName)如果您希望以降序索引某个列中的值,您可以在列名称之后添加保留字 DESC:CREATE INDEX PersonIndexON Person (LastName DESC)假如您希望索引不止一个列,您可以在括号中列出这些列的名称,用逗号隔开:CREATE INDEX PersonIndexON Person (LastName, FirstName) 7.5全文索引MySQL从3.23.23版开始支持全文索引和全文检索,FULLTEXT索引仅可用于 MyISAM 表;他们可以从CHAR、VARCHAR或TEXT列中作为CREATE TABLE语句的一部分被创建,或是随后使用ALTER TABLE 或CREATE INDEX被添加。对于较大的数据集,将你的资料输入一个没有FULLTEXT索引的表中,然后创建索引,其速度比把资料输入现有FULLTEXT索引的速度更为快。不过切记对于大容量的数据表,生成全文索引是一个非常消耗时间非常消耗硬盘空间的做法。–创建表的适合添加全文索引CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), FULLTEXT (content));–修改表结构添加全文索引ALTER TABLE article ADD FULLTEXT index_content(content)–直接创建索引CREATE FULLTEXT INDEX index_content ON article(content) 7.6索引的优化:索引的好处在于搜索的优化,但过多的使用索引会造成滥用。索引的缺点:提高查询速度,降低更新表的速度。点用大量磁盘空间。在大数据量时需要考虑索引的优化。1. 何时使用聚集索引或非聚集索引?动作描述使用聚集索引使用非聚集索引列经常被分组排序使用使用返回某范围内的数据使用不使用一个或极少不同值不使用不使用小数目的不同值使用不使用大数目的不同值不使用使用频繁更新的列不使用使用外键列使用使用主键列使用使用频繁修改索引列不使用使用事实上,我们可以通过前面聚集索引和非聚集索引的定义的例子来理解上表。如:返回某范围内的数据一项。比如您的某个表有一个时间列,恰好您把聚合索引建立在了该列,这时您查询2004年1月1日至2004年10月1日之间的全部数据时,这个速度就将是很快的,因为您的这本字典正文是按日期进行排序的,聚类索引只需要找到要检索的所有数据中的开头和结尾数据即可;而不像非聚集索引,必须先查到目录中查到每一项数据对应的页码,然后再根据页码查到具体内容。其实这个具体用法我还不是很理解,只能等待后期的项目开发中慢慢学学了。2. 索引不会包含有NULL值的列只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。3. 使用短索引对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。4. 索引列排序MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。5. like语句操作一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。6. 不要在列上进行运算例如:select * from users where YEAR(adddate)<2007,将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:select * from users where adddate<’2007-01-01′。关于这一点可以围观:一个单引号引发的MYSQL性能损失。最后总结一下,MySQL只对一下操作符才使用索引:<,<=,=,>,>=,between,in,以及某些时候的like(不以通配符%或_开头的情形)。而理论上每张表里面最多可创建16个索引,不过除非是数据量真的很多,否则过多的使用索引也不是那么好玩的,比如我刚才针对text类型的字段创建索引的时候,系统差点就卡死了。 八、视图视图是一张虚拟表(逻辑表),它被定义为有连接的SELECT语句。视图与表类似。优点:是允许简单复杂查询,有助于限制对特定用户的数据访问,并提供额外的安全层,实现向后兼容。缺点:因为视图数据是基于基表,所以查询速度慢;表依赖关系(改基表结构时会影响视图) CREATE VIEW 语句在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。注释:数据库的设计和结构不会受到视图中的函数、where 或 join 语句的影响。CREATE VIEW view_name ASSELECT column_name(s) FROM table_name WHERE condition 样本数据库 Northwind 拥有一些被默认安装的视图。视图 "Current Product List" 会从 Products 表列出所有正在使用的产品。这个视图使用下列 SQL 创建:CREATE VIEW [Current Product List] ASSELECT ProductID, ProductName FROM Products WHERE Discontinued=No 我们可以查询上面这个视图:SELECT * FROM [Current Product List] 8.1SQL 更新视图即更新视图中的数据。注意:更新的列的数据只能是基表中存在的列。Update 视图名SET列名 = 表达式WHERE 条件 8.2SQL 撤销视图DROP VIEW SyntaxDROP VIEW view_name 九、MySQL编程DELIMITER的作用:告诉MYSQL解释器,该段命令是否已经结束,MYSQL可以执行了。默认情况下,delimiter是分号Delimiter //Create procedure proc_1(out param int)Begin Select count(*) into param from t;End;// 9.1变量声明、赋值在MYSQL存储过程中定义变量有两种:第一种:使用set或select直接赋值,变量名以@开头Set @a = 1000; 第一种:用declare关键字声明,在存储过程中,也称存储过程变量Declare a int default 1000; 两者的区别是: 在调用存储过程时,以DECLARE声明的变量都会被初始化为 NULL。而会话变量(即@开头的变量)则不会被再初始化,在一个会话内,只须初始化一次,之后在会话内都是对上一次计算的结果,就相当于在是这个会话内的全局变量。 变量不区分大小写,指定类型。 DECLAREa int;SET a := 10; 或 SET a = 10;SELECT a := 100;SELECT a := MAX(sal) FROM emp; 打印SELECT @a;SELECT a; 9.2控制语句IF条件判断语句IF expression THEN statements;END IF; IFexpression THEN statements;ELSE else-statements;END IF; IF expression THEN statements;ELSEIF elseif-expression THEN elseif-statements;...ELSE else-statements;END IF;9.3CASE语句第一种:判断范围之间SELECTCASE WHEN sal<3500 THEN ‘加油’ WHEN sal=3500 THEN ‘刚好’ ELSE ‘交税’END AS ‘提示’FROM emp; 第二种:判断具体值SELECTCASE sal WHEN 1000 THEN ‘只有1000’ WHEN 2000 THEN ‘只有2000’ ELSE ‘我只有3000’END AS ‘提示’FROM emp; 9.4循环语句WHILE……DO……END WHILEREPEAT……UNTIL END REPEATLOOP……END LOOPGOTO WHILE……DO……END WHILE循环Delimiter $$ // 定义结束符为$$Drop procedure if exists wk; //删除已有的存储过程Create procedure wk() //创建新的存储过程BeginDeclare i int;Set i=1;While i<11 do Insert into user(uid) values (i);Set i = i +1;End while;End $$ //结束定义语句Delimiter ; //把结束符回复为; LOOP循环Delimiter $$Create procedure wk(a int)BeginDeclare sum int default 0;Declare i int default 1;loop_name:loop --循环开始 If i>a then Leave loop_name; --判断条件成立则结束循环,好比java中的break End if; Set sum = sum + i; Set i = i + 1;End loop; --循环结束Select sum; --输出结果End $$Delimiter ; REPEAT……UNTIL END REPEAT循环Delimiter $$Drop procedure if exists wk;Create procedure wk()BeginDeclare i int;Set i =1;Repeat Insert into user(uid) values(i+1); Set i=i+1;Until i>=20 END REPEAT; //当i>=20时结束循环End $$ 十、存储过程为以后的使用保存的一条或多条MYSQL语句的集合,因此也可以在存储过程中加入业务逻辑和流程。可以在存储过程中创建表,更新数据,删除数据等。 使用策略:(1)可以通过把SQL语句封装在容易使用的单元中,简化复杂的操作。(2)可以保证数据的一致性。(3)可以简化对变动的管理。10.1创建存储过程DELIMITER $$ CREATE /*[DEFINER = { user | CURRENT_USER }]*/ PROCEDURE `db_abc`.`12`() /*LANGUAGE SQL | [NOT] DETERMINISTIC | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } | COMMENT 'string'*/ BEGIN END$$ DELIMITER ; DELIMITER //CREATE PROCEDURE GetAllProducts() BEGIN MYSQL语句 END//DELIMITER ; 第一个命令是DELIMITER //,它与存储过程语法无关。 DELIMITER语句将标准分隔符 - 分号(;)更改为://。 在这种情况下,分隔符从分号(;)更改为双斜杠//。为什么我们必须更改分隔符? 因为我们想将存储过程作为整体传递给服务器,而不是让mysql工具一次解释每个语句。在END关键字之后,使用分隔符//来指示存储过程的结束。 最后一个命令(DELIMITER;)将分隔符更改回分号(;)。 使用CREATE PROCEDURE语句创建一个新的存储过程。在CREATE PROCEDURE语句之后指定存储过程的名称。在这个示例中,存储过程的名称为:GetAllProducts,并把括号放在存储过程的名字之后。 BEGIN和END之间的部分称为存储过程的主体。将声明性SQL语句放在主体中以处理业务逻辑。 在这个存储过程中,我们使用一个简单的SELECT语句来查询products表中的数据。10.2调用存储过程CALL STORED_PROCEDURE_NAME();十一、触发器1. 简介(1)触发器是一个特殊的存储过程,它是MYSQL在insert\update\delete的时候自动执行的代码块。(2)触发器必须定义在特定的表上。(3)自动执行,不能直接调用。作用:监视某种情况并触发某种操作。触发器的思路:监视it_order表,如果it_order表里面有增删改的操作,则自动触发it_goods里面增删改的操作。比如新添加一个订单 ,则it_goods表,就自动减少对应商品的库存。比如取消一个订单,则it_goods表,就自动增加对应商品的库存减少的库存。 2. 触发器四要素监视地点(table)监视事件(insert\update\delete)触发时间(after\before)触发事件(insert\update\delete) 3. 创建触发器Create trigger trigger_nameAfter/before insert/update/deleteOn table_nameFor each rowBegin SQL语句:End 案例:购买一件商器,减少1个库存。 4. 删除触发器Drop trigger trigger_name 5. 查看触发器Show triggers 十二、数据备份与还原备份数据可以保证数据库中数据的安全,数据库管理员需要定期的进行数据库备份。1. 使用mysqldump命令备份Mysqldump -u username -p dbname table1 table2 …… > backupName.sql 案例:将db_book备份到d盘下Mysqldump -u root -p db_book > d:\db_book.sql SQL SELECT INTO 实例 - 制作备份复件下面的例子会制作 "Persons" 表的备份复件:SELECT *INTO Persons_backupFROM PersonsIN 子句可用于向另一个数据库中拷贝表:SELECT *INTO PersonsIN 'Backup.mdb'FROM Persons 十三、Java连接MySQL数据库 1. 导入MySQL数据库驱动包 2. 编写MySQL数据库信息Private static final StringCNAME="com.mysql.jdbc.Driver";Private staticfinalStringURL="jdbc:mysql://127.0.0.1:3306/数据库名";Private static final String username=”root”;Private static final String password=”root”;或Private static final StringCNAME="com.mysql.jdbc.Driver";Private static final StringURL="jdbc:mysql://127.0.0.1:3306/数据库名?user=root&password=root";十四、MySQL存入汉字乱码解决方案第一步: 在创建数据库时设置编码:字符集:utf8 -- UTF-8 Unicode排序规则:utf8_general_ci 第二步:找到MySQL的安装路径的my.ini文件default-character-set=utf8 十五、SQL 能做什么?· SQL 面向数据库执行查询· SQL 可从数据库取回数据· SQL 可在数据库中插入新的记录· SQL 可更新数据库中的数据· SQL 可从数据库删除记录· SQL 可创建新数据库· SQL 可在数据库中创建新表· SQL 可在数据库中创建存储过程· SQL 可在数据库中创建视图· SQL 可以设置表、存储过程和视图的权限 十六、SQL DML 和 DDL可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。查询和更新指令构成了 SQL 的 DML 部分:· SELECT - 从数据库表中获取数据· UPDATE - 更新数据库表中的数据· DELETE - 从数据库表中删除数据· INSERT INTO - 向数据库表中插入数据SQL 中最重要的 DDL 语句:·CREATE DATABASE - 创建新数据库·ALTER DATABASE - 修改数据库·CREATE TABLE - 创建新表·ALTER TABLE - 变更(改变)数据库表·DROP TABLE - 删除表·CREATE INDEX - 创建索引(搜索键)·DROP INDEX - 删除索引
-
一 、JVM(数据类型、堆、栈) 目录 数据类型基本类型引用数据类型Java中的参数传递时传值呢?还是传引用?但是传引用的错觉是如何造成的呢?操作系统的堆和栈堆栈为什么jvm的内存是分布在操作系统的堆中呢?java虚拟机的生命周期java虚拟机与main方法的关系GC jvm jvm内存结构与操作系统内存布局进行类比说明运行时数据区图数据类型基本类型基本类型的变量保存原始值,即:他代表的值就是数值本身包括:byte:8位,最大存储数据量是255,存放的数据范围是-128~127之间。short:16位,最大数据存储量是65536,数据范围是-32768~32767之间。int:32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。long:64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。float:32位,数据范围在3.4e-45~1.4e38,直接赋值时必须在数字后加上f或F。double:64位,数据范围在4.9e-324~1.8e308,赋值时可以加d或D也可以不加。boolean:只有true和false两个取值。char:16位,存储Unicode码,用单引号赋值。returnAddress 数据只存在于字节码层面,与编程语言无关,也就是说,我们在 Java 语言中是不会直接与 returnAddress 类型的数据打交道的。引用数据类型引用类型的变量保存引用值。“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置包括:类类型,接口类型和数组。Java中的参数传递时传值呢?还是传引用? Java中没有指针的概念, 程序运行永远都是在栈中进行的,因而参数传递时,只存在传递基本类型和对象引用的问题。不会直接传对象本身。Java在方法调用传递参数时,因为没有指针,所以它都是进行传值调用但是传引用的错觉是如何造成的呢? 在运行栈中,基本类型和引用的处理是一样的,都是传值。所以,如果是传引用的方法调用,也同时可以理解为“传引用值”的传值调用,即引用的处理跟基本类型是完全一样的。但是当进入被调用方法时,被传递的这个引用的值,被程序解释(或查找)到堆中的对象,这个时候才对应到真正的对象。如果此时进行修改,修改的是引用对应的对象,而不是引用本身,即:修改的是堆中的数据。所有这个修改是可以保持的。 对象,从某种意义上说,是由基本类型组成的。可以把一个对象看作为一棵树,对象的属性如果也是对象,则也是一颗树(即非叶子节点),基本类型则作为树的叶子节点。程序参数传递时,被传递的值本身都是不能进行修改的,但是,如果这个值是一个非叶子节点(即一个对象引用),则可以修改这个节点下面的所有内容。堆和栈中,栈是程序运行最根本的东西。程序运行可以没有堆,但是不能没有栈。而堆是为栈进行数据存储服务,说白了堆就是一块共享的内存。不过,正是因为堆和栈的分离的思想,才使得Java的垃圾回收成为可能。 Java中,栈的大小通过-Xss来设置,当栈中存储数据比较多时,需要适当调大这个值,否则会出现java.lang.StackOverflowError异常。常见的出现这个异常的是无法返回的递归,因为此时栈中保存的信息都是方法返回的记录点。操作系统的堆和栈堆一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收,分配方式类似于链表。栈由操作系统自动分配释放,存放函数的参数值,局部变量值等。操作方式与数据结构中的栈相类似。为什么jvm的内存是分布在操作系统的堆中呢?因为操作系统的栈是操作系统管理的,它随时会被回收,所以如果jvm放在栈中,那java的一个null对象就很难确定会被谁回收了,那gc的存在就一点意义都莫有了,而要对栈做到自动释放也是jvm需要考虑的,所以放在堆中就最合适不过了。java虚拟机的生命周期声明周期起点是当一个java应用main函数启动时虚拟机也同时被启动,而只有当在虚拟机实例中的所有非守护进程都结束时,java虚拟机实例才结束生命。java虚拟机与main方法的关系main函数就是一个java应用的入口,main函数被执行时,java虚拟机就启动了。启动了几个main函数就启动了几个java应用,同时也启动了几个java的虚拟机。GC虚拟机的gc(垃圾回收机制)就是一个典型的守护线程。GC垃圾回收机制不是创建的变量为空是就被立刻回收,而是超出变量的作用域后就被自动回收。 jvm jvm内存结构与操作系统内存布局进行类比说明上图表明:jvm内存是存在于计算机内存中,并根据自身需求将内存划分为:pc寄存器、虚拟机栈、本地方法栈、jvm堆以及方法区,这些区域共同组成了运行时数据区,其中gc主要发生在堆区,栈由jvm自行管理pc寄存器:其主要职责是指示线程要执行的下一条指令的地址,具体执行过程参考下文:Class文件的执行过程栈:主要是有栈帧组成,每个栈帧代表一个方法,且位于栈顶的栈帧是当前正在执行的方法。堆:java中一切皆对象,所有对象都是在堆中生成,有gc垃圾回收器进行回收方法区:类似计算机的硬盘,主要存放class文件,其中class文件基本组织结构可以参考Class文件的内存信息 运行时数据区图 上图表明:方法区和堆是线程共享的,虚拟机栈、本地方法栈和程序计数器都是线程私有的,这里的程序计数器是线程私有的是因为线程可以被切换暂停的,当恢复运行时由程序计数器执行接着执行的指令地址。
-
二 、JVM (Java对象、对象引用类型) 目录 Java对象的大小测试对象引用类型强引用软引用弱引用虚引用 Java对象的大小这里要使用的是lucene提供的专门用于计算堆内存占用大小的工具类:RamUsageEstimator<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>4.0.0</version> </dependency>使用该第三方工具比较简单直接,主要依靠JVM本身环境、参数及CPU架构计算头信息,再依据数据类型的标准计算实例字段大小,计算速度很快,另外使用较方便。如果非要说这种方式有什么缺点的话,那就是这种方式计算所得的对象头大小是基于JVM声明规范的,并不是通过运行时内存地址计算而得,存在与实际大小不符的这种可能性。常用API//计算指定对象及其引用树上的所有对象的综合大小,单位字节 long RamUsageEstimator.sizeOf(Object obj) //计算指定对象本身在堆空间的大小,单位字节 long RamUsageEstimator.shallowSizeOf(Object obj) //计算指定对象及其引用树上的所有对象的综合大小,返回可读的结果,如:2KB String RamUsageEstimator.humanSizeOf(Object obj)测试 public static void main(String[] args) { Object o = new Object(); //计算指定对象及其引用树上的所有对象的综合大小,单位字节 System.out.println(RamUsageEstimator.sizeOf(o)); //计算指定对象本身在堆空间的大小,单位字节 System.out.println(RamUsageEstimator.shallowSizeOf(o)); //计算指定对象及其引用树上的所有对象的综合大小,返回可读的结果,如:2KB System.out.println(RamUsageEstimator.humanSizeOf(o)); System.out.println("一个Interger对象大小为:"+RamUsageEstimator.sizeOf(new Integer(1))); System.out.println("一个String对象大小为:"+RamUsageEstimator.sizeOf(new String("a"))); System.out.println("一个char对象大小为:"+RamUsageEstimator.sizeOf(new char[1])); System.out.println("一个ArrayList对象大小为:"+RamUsageEstimator.sizeOf(new ArrayList<>())); System.out.println("一个Object对象大小为:"+RamUsageEstimator.sizeOf(new Object())); System.out.println("一个Long对象大小为:"+RamUsageEstimator.sizeOf(new Long(10000000000L))); } 结果: 16 16 16 bytes 一个Interger对象大小为:16 一个String对象大小为:48 一个char对象大小为:24 一个ArrayList对象大小为:40 一个Object对象大小为:16 一个Long对象大小为:24对象引用类型从高到低依次:强引用(StrongReference)软引用(SoftReference)弱引用(WeakReference)虚引用(PlantomReference) 强引用就是我们一般声明对象是时虚拟机生成的引用,强引用环境下,JVM宁可抛出OOM(out of memory)异常也不会回收强引用所指向的对象,即GC(垃圾回收或垃圾收集)绝对不会回收强引用类型。由于GC绝不会回收强引用,所以它将可能导致内存泄漏。例: //object和str都是强引用 Object object = new Object(); String str = "hello"; String s = new String()软引用软引用用于描述一些还有用但并非必须的对象,一般被做为缓存来使用(比如网页缓存、图片缓存)。与强引用的区别是,软引用在垃圾回收时,虚拟机会根据当前系统的剩余内存来决定是否对软引用进行回收。如果剩余内存比较紧张,则虚拟机会回收软引用所引用的空间;如果剩余内存相对富裕,则不会进行回收。换句话说,虚拟机在发生OutOfMemory时,肯定是没有软引用存在的。例: SoftReference<String> sr = new SoftReference(new String("123")); System.out.println(sr.get());注意在垃圾回收器对这个Java对象回收前,SoftReference类所提供的get方法会返回Java对象的强引用,一旦垃圾线程回收该Java对象之后,get方法将返回null。所以在获取软引用对象的代码中,一定要判断是否为null,以免出现NullPointerException异常导致应用崩溃。弱引用弱引用用于实现一些规范化映射(WeakHashMap),其中key或者value当它们不再被引用时可以自动被回收。当你想引用一个对象,但是这个对象有自己的生命周期,你又不想介入这个对象的生命周期时,便可以用弱引用。同时弱引用也可以用来保存那些可有可无的缓存数据,和软引用一样,在内存充足时加速系统,在内存不足时便被系统回收。弱引用在系统GC时,只要一被发现,不管系统堆内存空间是否足够,都会将对象进行回收,一旦被回收便会被加入到相关联的引用队列中。但是,由于垃圾回收器的线程通常优先级很低,所以并不一定能很快发现持有弱引用的对象,所以弱引用的生命周期是从被创建到下一次GC发送之前。例: WeakReference<String> wr = new WeakReference(new String("123")); System.out.println(wr.get()); System.gc(); //通知JVM的gc进行垃圾回收 System.out.println(wr.get());注意第二个输出结果是null,这说明只要JVM进行垃圾回收,被弱引用关联的对象必定会被回收掉。不过要注意的是,这里所说的被弱引用关联的对象是指只有弱引用与之关联,如果存在强引用同时与之关联,则进行垃圾回收时也不会回收该对象(软引用也是如此)。虚引用 虚引用又叫幽灵或幻影引用,主要用来跟踪对象被垃圾回收器回收清理的活动,提供比Java清理机制更灵活的处理方式。虚引用是所有引用类型中最弱的一个,如果一个对象拥有一个虚引用,那它便和没有被引用一样,随时可能被GC回收,而且GC在回收时会直接销毁持有该引用的对象,并把虚引用加入引用队列中。除此之外需要注意的一点是,当虚引用试图通过get()方法取得强引用时,无论强引用是否存在,总是会失败,即获得的返回值永远为null。虚引用与软引用和弱引用的区别在于:虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。例:将虚引用和引用队列结合使用,可以看到虚引用的对象被垃圾回收后,虚引用将被添加到引用队列 String str =new String("123"); ReferenceQueue rq=new ReferenceQueue(); WeakReference wr=new WeakReference(str); PhantomReference pr=new PhantomReference(str,rq); Object obj=wr.get(); System.out.println(obj); System.out.println(wr.get()); str=null; System.out.println(pr.get()); System.gc(); System.runFinalization(); System.out.println(rq.poll()==pr); //rq.poll()函数作用为检索并移除文件的头 //rq.poll(); System.out.println(rq.poll()==pr); 结果: 123 123 null false false